




































Receive the latest updates on growth and AI workflows in your inbox every week
The most common frustration with today’s current generative artificial intelligence systems is that…sometimes it comes out like gobbledegook.
Sure, it might sound just fine. But if you dig deeper into the topic, it can be filled with jargon that doesn’t make sense, missed citations for important facts, or include completely made-up claims. (You’ve seen the creepy AI-generated imagery where people have seven fingers, right? That’s what’s happening across all mediums.)
There are several reasons that this occurs from a technological perspective. It’s easy to picture something sentient on the other side of the cursor, the same way there is one when we send an email or a text and get a reply from a friend or colleague. But generative AI isn’t crafting a personalized piece of text for you. It works by quickly analyzing language patterns—the terms, phrases, and sentences that often go together around a certain topic—and spitting them back out. There’s no “thinking” going on.
That’s why you can’t treat ChatGPT or Claude like a search engine (yet), even though it scrapes the internet for this content. With the right inputs, though, you can train AI out of hallucinations. And we’re seeing them less and less, according to Blaine Bassett, former Product Marketing Manager at Ironclad. “Models are trained on sets of data, and each round helps cross-check all of its references. Hallucinations are decreasing across all model providers, and I don’t think it will be a problem in a year or two,” he says.
The other reason these hallucinations happen comes back to how organizations train their models. You already know that without great data, you can’t make the right decisions. The same is true for artificial intelligence. If you train generative models solely on their own output, it creates a phenomenon known as AI model collapse.
What is AI model collapse?
AI model collapse refers to the downward spiral of quality from AI as models move from learning from human-generated output (such as existing books, articles, or web pages) and to training off of previously generated content, or synthetic data. Doing so produces increasingly inaccurate results, to the point where the model becomes useless.
The idea of model collapse is relatively new. “We find that indiscriminate use of model-generated content in training causes irreversible defects in the resulting models, in which tails of the original content distribution disappear,” writes Ilia Shumailov et. al. for scientific journal Nature in 2024. “[This is a] a degenerative process whereby, over time, models forget the true underlying data distribution, even in the absence of a shift in the distribution over time.”
What does this look like in practice? John Burden, et. al. explain this phenomenon for Harvard Law’s Jolt like this:
If 1% of people wear red hats, 99% wear blue hats, and we randomly sample 20, there’s a good chance all 20 wear blue hats, so we might conclude that everyone wears blue hats and no one wears red hats. Yet, an AI trained on this sample might only generate text or images referring to people wearing blue hats, and never red hats. If the output of this AI starts to contaminate Internet data, the proportion of references to red hats will go down, so the next data collection might sample from a pool where 99.5% of people wear blue hats, and 0.5% wear red hats. An AI trained on that dataset is even more likely to conclude that everyone wears a blue hat. Eventually, as this process is repeated many times, all references to red hats will be totally lost.
This results in higher probability of errors and gibberish. More importantly, though, model collapse limits the amount and nature of data we as people have access to, building recursive echo chambers that diminish or eliminate at best, nuance, and at worst, fundamental fact and truth.
What model collapse means for the future of artificial intelligence
There are so many benefits to using artificial intelligence. When we asked legal teams for the State of AI in Legal Report how they’re using AI, we found that it’s helped them conduct research more quickly, save time by automating menial tasks, and freed up more time for teams to be more strategic, doing high-impact, interesting work instead of cut-and-paste drudgery.
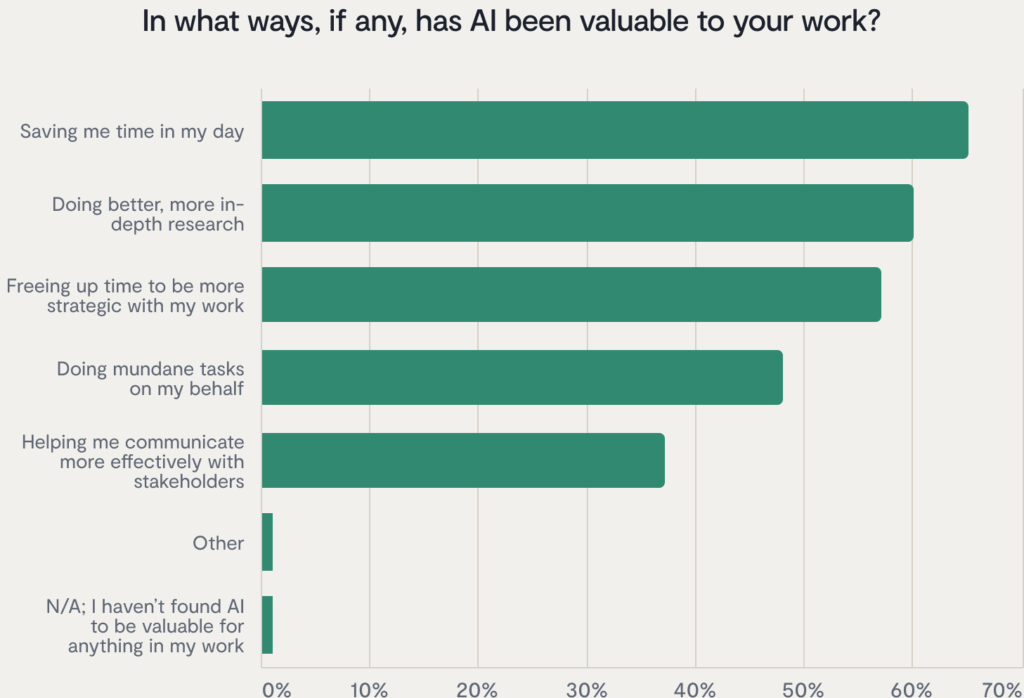
But AI only provides these benefits because it produces accurate, fast results. Inaccurate outputs from model collapse destabilizes the entire system because it makes it impossible to trust whether or not what it provides is real.
The reason model collapse concerns researchers is because as generative AI becomes more prevalently used, there’s a higher likelihood that AI will encounter AI-generated content on the web or through other sources as it trains, starting a recursive loop that will be difficult to fix.
Model collapse hasn’t happened yet, but it remains a risk that means annoying hallucinations could become more likely, instead of less. This can look like nonsensical, inaccurate, or repetitive results that sound the same no matter the prompt.
How to prevent AI model collapse
On a broader level, we’re seeing teams at OpenAI, Meta, and IBM talk more about AI governance for their models, which detect bias or performance issues and work to mitigate them in real-time. There’s also a push from researchers and companies alike to retain high-quality, human-created data as training models. Projects like the Data Provenance Initiative, spearheaded by MIT researchers, are working to collect and audit robust text, speech, and video data sets to map the current AI landscape.
AI model collapse is bigger than any individual or organization, but there are safeguards you can implement within your team to make sure that you’re getting the most out of your AI workflows (and to save you all time editing and fact-checking on the back end.):
Using targeted, focused prompts with generative AI
Part of why any hallucinations happen is because of poor prompt engineering. “The broader the question, the more AI can snowball into believing it’s saying something accurate,” says Bassett. “Remember, it’s a math equation, so you need to provide the right inputs to get the right outputs. Be as specific as possible with your requests, which can prevent some of this recursive logic from happening.”
The mistake most people make is that they treat generative AI like a search engine. Instead, you’ll need to feed it directly with the data you’re hoping to analyze, whether that’s proprietary data from your organization or specific resources you’ve already pulled. An example of this would be to upload a legal case PDF and ask it for a one page summary with key takeaways and action items. That way, you’re directly delivering the data in the prompt (the input) that the model needs to deliver the answers you’re looking for (the output.)
Choosing the right tasks to outsource to AI
At Ironclad, we’re big proponents of what AI can do. 74% of legal professionals are using AI for legal work—90% of which plan to use AI more frequently next year. But it can’t do everything perfectly right now—it’s one of the reasons a real person wrote this article instead of outsourcing it to AI!
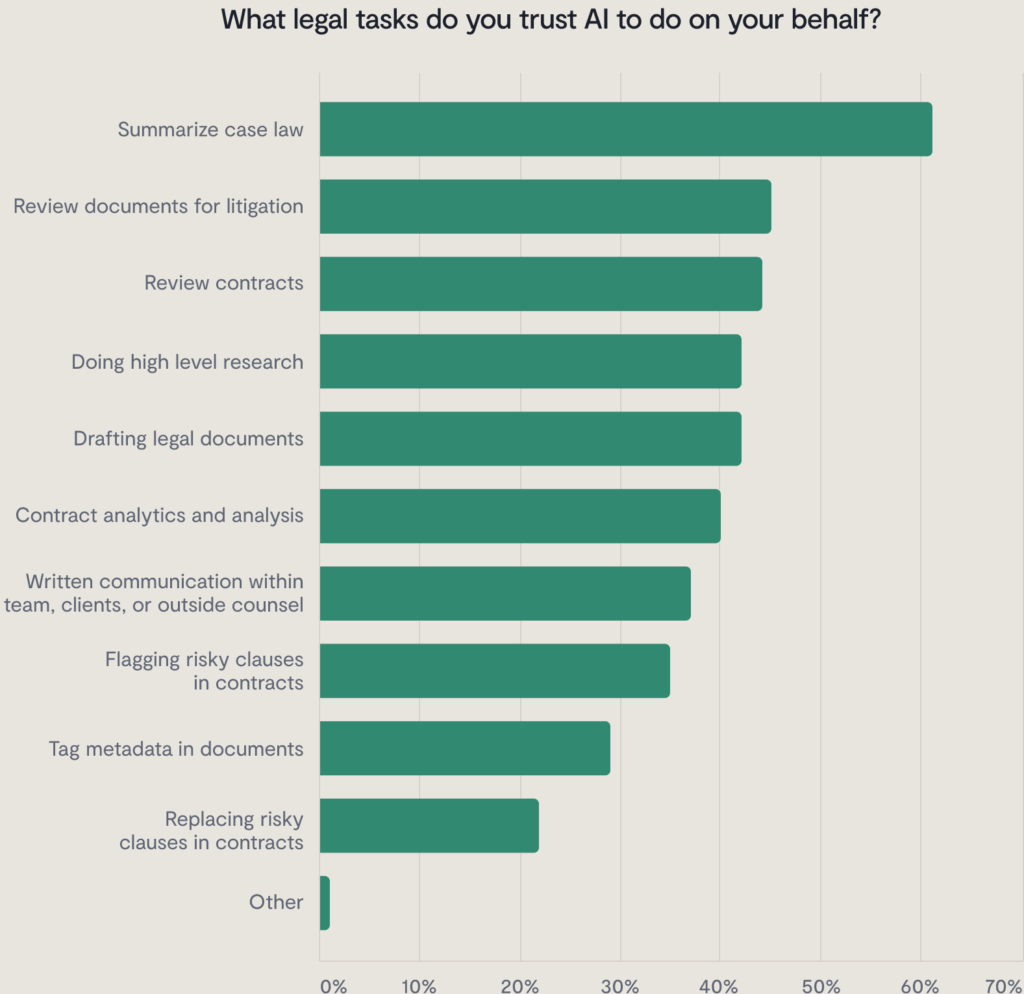
You want to use artificial intelligence for the tasks that it’s already best at—and that’s the kind of tasks that require a lot of data processing and analysis, either quantitative or qualitative.When we asked legal professionals exactly how they’re using AI for the State of AI in Legal Report, they focused on the parts of the contract management process that no one enjoys doing. That looks like tagging metadata in your documents, flagging risky clauses for your team to review in your contracts, or analyzing existing contracts to find patterns of performance.
Creating proprietary, secure GPTs that are trained on your organization’s data
Instead of relying on open-source AI for your organization, creating secure GPTs designed with your industry and data in mind can get around this issue.
This requires extensive training on your customer and internal data for the model to get it right, but doing so has significant benefits to your organization as a whole:
- A proprietary GPT can serve as the arbiter of brand, maintaining your brand’s voice and tone across multiple assets
- Synthesizing customer data from around the organization allows you to “talk” to an average customer or persona at any time for their pain points or issues, rather than having to interview existing customers
- You can find cross-functional patterns for process improvements or find data that your organization already has but you, in your current role, may not easily access because of silos or systems that don’t “talk” to one another
This comes back to making sure your data sets are the right data sets for AI to train with. Owning the model allows you more control over the data provenance and hygiene, giving you more peace of mind.
Choose software applications for the most important tasks
We’ve talked a lot about how model collapse can render something like ChatGPT completely useless. But what does that look like inside a piece of software, like a customer service chatbot or artificial intelligence-powered features, like those we offer at Ironclad?
An application gets around the majority of the model collapse issue precisely because there are human engineers checking and double-checking the accuracy and ability of the artificial intelligence every day. “The job of an application layer, like Ironclad, is to give the user more pointed workflows, which complete set tasks,” says Bassett.
Humans in the loop also makes sure that the data inputs remain high-quality, human-generated, and focused. Says Bassett, “For example, if your question is to identify the risk associated with an indemnification clause, that’s much more specific than asking what the risk is in the contract as a whole, or the general risk tied to indemnification clauses. The right CLM can help you use AI more effectively, since we’re programming it to answer the questions that are the most helpful.”
Keeping a human-first approach for your workflows
Every tool has its limitations. Organizations today are awash in data, but often struggle to make proper use of it—or leave it trapped in systems or processes that mean people throughout the organization can’t access it properly.
Take your contracts, for example. If you haven’t digitized them, any time you have a question about supplier obligations or renewal dates, someone has to physically visit the file to try to find a copy. And if you have digitized them, but the files remain on someone’s individual desktop or in a document software that only stores the files, you basically have to do the same search-and-find song-and-dance, just digitally. Model collapse is a similar limitation on data, but its scale (the entire Internet) is what is cause for concern.
The best way to prevent any issues from this is to keep a human in the mix. You still need the same amount of people to get a job done with AI, but the kind of work they do has changed. Instead of needing a person to go grab a file and take a red pen to it, for example, you can have AI do the first pass, flagging concerning clauses for your team to review.
The point is, no matter how great AI gets at this task, your team still has to review it and approve it. Think of AI more as an assistant than as a replacement, so you’re preserving the accuracy, diversity, and authenticity that makes your human knowledge valuable, while still relying on technology that can accelerate progress and make your life easier. We’ll talk more about this in a moment.
Model collapse risk doesn’t mean you should stop using AI
Far from it. But it does mean you need to use AI with the same discerning judgement you bring to your legal work.
If you think about how the American Bar Association’s Model Rules of Professional Conduct requires lawyers to provide competent representation to clients, part of this is about understanding the assistive technology you’re using and its limitations.
That means even if you’re using AI to create, review, or analyze your agreements, you should still be able to explain how it works, how it came to its reasoning for swapping one clause over another, and what evidence and arguments are relevant to a given case. Or if you’re using AI to help you generate a contract, you’re checking it over to make sure it’s hit all of the clauses you need.
AI is just a tool—don’t let it do the thinking for you.
Learn everything you need to know about AI for legal teams
Legal documents are a great use case for AI because contracts are predictable, standardized, and accurate—all aspects of structured data that AI is designed to analyze. We’ve compiled use cases across multiple teams, plus how real teams are currently using AI tools, in our Legal AI Handbook.
Ironclad is not a law firm, and this post does not constitute or contain legal advice. To evaluate the accuracy, sufficiency, or reliability of the ideas and guidance reflected here, or the applicability of these materials to your business, you should consult with a licensed attorney.


