


When most people think of Ironclad, their minds don’t typically jump straight to the data analytics side of the business. However, contracts and the way users interact with them is data that’s extremely valuable, making Ironclad a data treasure trove.
We need data to run our business and inform future product decisions, and that’s where our small-but-mighty data analytics team comes in. The analytics team members operate essentially as data treasure hunters.
We gather the right data, do exploratory analysis, create dashboards, forecast key metrics, and make recommendations so that Ironclad’s business moves forward in a data-informed way.
We operate as cross-functional liaisons between Ironclad’s product, customer success, sales ops, marketing, and finance teams to make sure everyone is speaking the same data language and gathering valuable insights from these findings.
So, how do we do it? And what do we recommend other early data teams at startups do to promote and expand a data-centered culture? Let’s dig in.
Ensure data cleanliness and data inspection
First, get a firm understanding of your data.
Start by asking, what data do we have already? Do we have both event data (i.e. tracking data on contract completions, page visits, and collaboration history) and current state data (i.e. the latest state of information pertaining to users, customer accounts, or contracts)? What about data from external systems like Salesforce? What kind of data is flowing from other apps and tools we use?
Then, how do we implement data tracking and storing? To get a better sense of your data, it’s helpful to draw out your company’s data ecosystem. We’ve provided ours below.
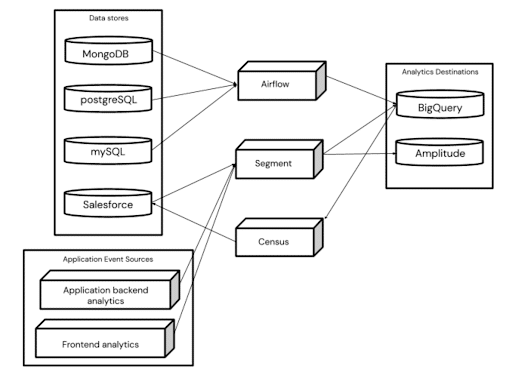
Ironclad's data ecosystem
Once we got a better understanding of our own data ecosystem, we can begin asking deeper questions like:
- How complete is our data?
- Is the right information accessible?
- What’s missing from our tracking?
- Are there duplicates in the data?
- Which edge cases does our data not account for?
- Is the data accurate?
After doing your own inspection, talk to others across the company (i.e. product managers, engineers, and business stakeholders) to get their perspective on data quality at your company and begin to get a holistic picture of which data quality items you should prioritize tackling. Then, create a data quality gap list and try to fill them based on the highest return on investment.
Remember that bad data in means bad data out! Implementing good data quality practices early on will make it easier for your startup as it begins to scale rapidly.
Use dim tables for your most important data
Once you have tackled most of your data quality issues, it’s important to create dimension (dim) tables of your most important data that you use over and over again. For Ironclad, that looks like data on customer companies, their users, and their contracts.
The schema should look something like this:
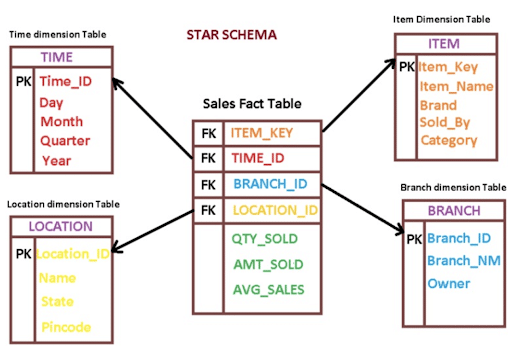
Schema
These tables should be easy to understand, update with new information nightly, and help new folks onboard to the data ecosystem by understanding where the most central data and its subsequent information lives.
The tools we use at Ironclad
All of this data inspection and cleaning would not be possible if it weren’t for the helpful tools we use.
Data warehousing – BigQuery, MongoDB, and Postgres
Dashboarding – DataStudio, Tableau, and Amplitude
Data Science Exploration – Jupyter Notebooks
ETL – Segment, Census, Airflow, and Fivetran
Other tools we’ll consider in the future include Looker, Hex, Mode, and dbt.
Which metrics should you care about?
After your data and tooling is cleaned and organized, you can start gathering important and useful metrics for business stakeholders. Ironclad is a B2B SaaS company, meaning our most important metrics focus on acquiring, retaining and monetizing customers (refer to this article for more information). We customize this metrics approach based on who our audience is— each group has different business questions it needs answering:
The executives and/or board want to focus on easy-to-understand, industry-standard metrics like Gross Renewal Rate (GRR), Net Renewal Rate (NRR), logo churn and growth per quarter, WAU/MAU growth, employee growth and attrition rates, Annual Recurring Revenue (ARR), and quarterly bookings. All of these metrics should be measured against the target/goal value for each of these metrics to contextualize how the company is tracking relative to industry standard.
Meanwhile, HR might want to focus on candidate close rate, the marketing team may focus on MEL to SAO conversion, finance may prioritize bookings, revenue, dollars renewed, or cash burn, and the customer success team may prioritize tracking the distribution of customer health scores across the customer base to predict churn and renewal rates.
The Product Analytics may focus on time for a customer to complete a certain action for the first time, growth in usage of a feature over time, feature use case penetration (i.e. what % of the user base per customer account is using a certain feature), which kinds of users are adopting and retaining certain future usage, behavioral differences in product usage between segments, or sign up conversion funnels.
Get product teams to prioritize data
Two big areas of investment right now for the Ironclad team are data quality and data culture. We found that establishing a data culture within each product and engineering team was the best way to start expanding our data culture. At Ironclad, we have about seven core product teams and we’re beginning to meet with each team in a monthly “data huddle” to discuss key questions and data needed to inform each team’s product feature value. Our data huddle template is provided below—Feel free to get started filling out your own template here!


To accomplish this, we need to have buy-in from product managers in strongly tracking their respective product adoption via descriptive instrumented events. Engineers need to implement analytics tracking of new events and features that correspond to what that team is releasing that week. There should be a ticketing method in JIRA to implement new events. To keep up progress on this front, there should be semi-regular analytics 1:1 sessions with product managers to dive deeper into the questions brought up in each data huddle. It’s important to try to make talking about data embedded into each product team’s workflow.
These huddles help us see what each product team is prioritizing and help us craft team-specific north star metrics and how they relate to product team and company-wide priorities. After settling on team north star metrics, we use a product metrics dashboard weekly to track against these metric goals.
Scope data projects
Whenever we have high-impact exploratory data projects to work on (i.e. exploring product usage data in order to update pricing, making a dashboard for customer benchmarking, or gather intel on improving customer time to value), we recommend creating a data scoping document, similar to a product spec. We fill this template out whenever we have big projects to collaborate on.

Data scoping document
The goal is to provide structure behind the big, ambiguous data project we’re embarking on. It helps us figure out what exploratory questions to prioritize, set up rough timelines, and loop in and gather feedback from the right stakeholders. It’s best to keep this document relatively short (1-2 pages) to not lose focus on the main goal of the project.
After the initial motions of this project are set, feel free to customize timelines and expectations but keep checking back on this data scoping document to make sure the project isn’t going off on tangents and is still delivering value in a timely manner.
Over-communication is key
So, how do we make sure the work we do is well-socialized and documented?
We start with an analytics Slack channel where folks across the company can ask analytics questions or post their findings. Furthermore, we have product-team-specific analytics channels where we can follow up on action items from our data huddles mentioned above.
If we have deeper analytics questions or problems that need tackling, we usually discuss them in cross-functional analytics roundtables where data-adjacent folks across sales ops, marketing ops, and revenue ops meet with the data analytics team.
Since Data Analytics sits on the Engineering, Product, and Design (EPD) team, we also do read outs in our weekly EPD all-hands meetings where we talk about the current trends of our topline metrics as well as important projects we’re currently working on so the rest of the EPD team can get a sense of what we’re prioritizing. Sometimes we broadcast what we’re doing across the company in one of our biweekly, company-wide Show and Tell sessions.
To document our work, we have a data analytics team-specific Coda and google drive folder where we document code, dashboard links, meeting notes, project documentation, decks, and hiring material.
Where we’re going next
We want to advance our data analytics and data science methodologies. Some examples include trying out more robust A/B testing, forecasting quarterly renewal rates more accurately using our internal health score, and clustering users based off of product usage to determine better pricing strategy.
We’re also interested in building out our modern data stack by procuring new tools as well as strategic initiatives like product-led growth and self-service analytics.
At the end of the day, we want to become even more of an insights-generating entity and partner more closely with executive stakeholders to influence product and business decisions.
Hiring
We can’t talk about the future without talking about growing the team. Most recently, we grew our team from 1 to 2 after we hired an intern-turned-full-time-teammate from the Women in Data Slack community (Data Angels) that I run.
In the future, we’d love to expand the team to include data engineers, data scientists, analytics interns, and a Head of Business Intelligence. Soon enough, there will be several data analysts embedded on each team across the company and we will have one unified data analytics org with all business-intelligence related roles under one umbrella. There’s still so much growth to do!
Explore our career opportunities here
Written by Jessica Cherny, Data Analyst II
Ironclad is not a law firm, and this post does not constitute or contain legal advice. To evaluate the accuracy, sufficiency, or reliability of the ideas and guidance reflected here, or the applicability of these materials to your business, you should consult with a licensed attorney. Use of and access to any of the resources contained within Ironclad’s site do not create an attorney-client relationship between the user and Ironclad.
- Ensure data cleanliness and data inspection
- Use dim tables for your most important data
- The tools we use at Ironclad
- Which metrics should you care about?
- Get product teams to prioritize data
- Scope data projects
- Over-communication is key
- Where we’re going next
- Hiring
Want more content like this? Sign up for our monthly newsletter.


