




































Table of Contents
- TL;DR
- Background: One Redis to rule them all
- Phase 1: Early split for sessions & permissions
- Phase 2: The incident that changed our minds
- Phase 3: Defining the Redis workstream
- Theme 1: Multi-instance & tiering strategy
- Theme 2: Making Redis observable
- Theme 3: Pub/Sub and SSE – From wildcard fan-out to exact subscriptions
- Theme 4: Isolating AI workloads
- Theme 5: Connections and lifecycle
- Theme 6: Durability and Redis Cluster
- Theme 7: Cleaning up “Redis misfits”
- Results
- What’s next
Receive the latest updates on growth and AI workflows in your inbox every week
At Ironclad, we build the contract lifecycle platform that thousands of legal, sales, and procurement teams rely on to draft, negotiate, and manage their agreements. Like a lot of growing companies, many of our infrastructure decisions were made when we were much smaller, including our Redis infrastructure, serving as cache, coordination bus, job queue, and session store. For years it worked. This post is the story of what happened when it stopped, and how we rebuilt Redis into something we’d trust at 10× our current load, with a path to 100x.
TL;DR
For years we ran the classic startup pattern: one shared Redis instance that did a bit of everything – caching, pub/sub, background job coordination, AI features, and user sessions. It worked, until it didn’t.
As product usage grew, and especially as we added AI-heavy features, we hit several critical production issues early this year caused by exhausting our Redis allocations. The tipping point was realizing Redis was no longer just transparent infrastructure; it had become a bottleneck and a failure domain for the app.
This post is the story of how we responded. We re-architected Redis from a single shared instance into an isolated, observable, multi-instance system with targeted fixes for pub/sub, AI workload isolation, and stronger durability for the few flows that need backing-store semantics.
Today, we’re comfortable saying our Redis usage is stable at current traffic with roughly 10x headroom, and we have a concrete plan to get to 100x without rewriting the world.
This write-up focuses less on our exact architecture and more on how we investigated, what we learned, and the design decisions we made—the parts you can adapt to your own stack.
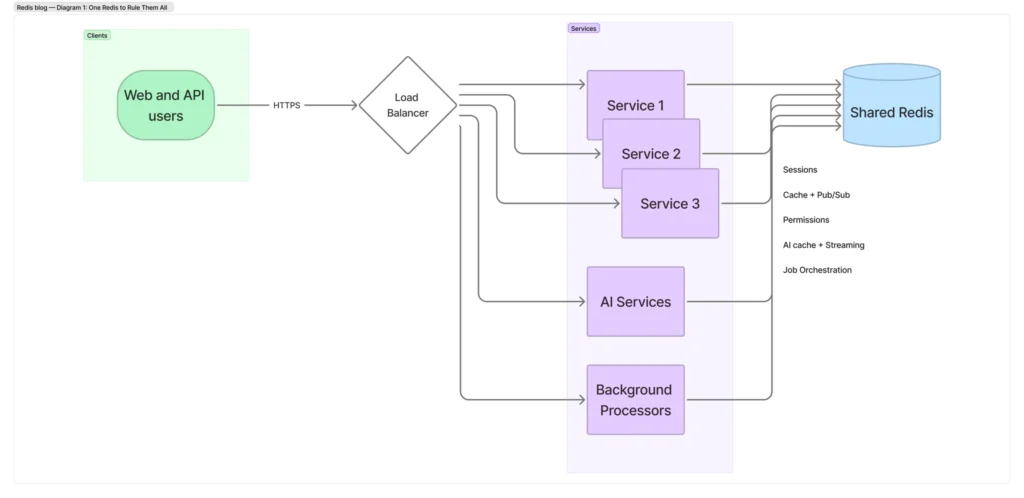
Background: One Redis to rule them all
Like many systems, we started with one managed Redis for everything: sessions and permissions, general caches, background-job orchestration, SSE/pub-sub, and AI state.
It was simple to operate and easy for new features to adopt, but over time that simplicity became a liability:
- Noisy neighbors: a burst in any one domain (e.g., bulk jobs, AI, SSE) could steal memory and CPU from everything else.
- Hard-to-attribute incidents: when Redis was “unhappy,” it wasn’t obvious which feature was responsible.
- Mixed semantics: the same instance was being used as a best-effort cache, a coordination bus (pub/sub), a durable work queue and a session store (user-visible if evicted).
We felt that pain earliest in IAM, where losing sessions or permissions data mattered far more than losing a normal cache entry, and that drove our first Redis split.
Phase 1: Early split for sessions & permissions
Our first concrete step away from the “one Redis” model happened in IAM.
Problem
Sessions and permissions are not like normal cache entries: they sit on the user-visible critical path, and losing them during peak traffic is especially painful. In practice, they behave more like backing-store data than best-effort cache entries. Keeping them on the same Redis as less critical caches and background job queues meant any Redis incident was immediately user-visible.
Constraints
We wanted:
- Dedicated capacity and eviction policy for sessions and permissions.
- TLS-secured, highly available instances (we treat them like a backing store, not a best-effort cache).
- A safe migration pattern other teams could reuse.
Design and migration pattern
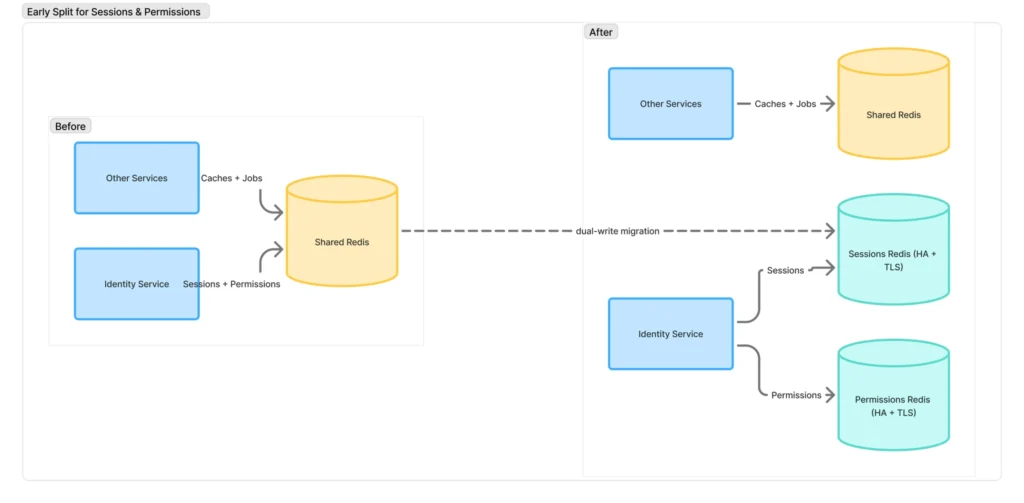
Each instance had its own sizing assumptions, eviction policy, monitoring, and alerting. We also built a five-stage migration runbook that we now use across Redis migrations.
This gave us:
- A pattern (“dual write, dual read, cutover”) that could be applied to future Redis migrations.
- A containment story: if some cache blows up, it doesn’t immediately log users out.
Phase 2: The incident that changed our minds
The inflection point was a production outage driven by the interaction between:
- AI assistant flows, sending large real-time updates over SSE.
- A retry storm in a separate subsystem, amplifying connection and command volume.
What actually went wrong
Two unrelated changes lined up badly: a feature began publishing larger-than-expected payloads, while another sub-system entered an aggressive retry loop. Because both shared the same Redis as core caches and other real-time traffic, the combination of large pub/sub messages, high fan-out from pattern subscriptions, and extra connection churn pushed Redis over its memory limit. That led to evictions, slowdowns, and eventually a crash/restart that took dependent services with it.
Lessons from the incident
The root issues were not exotic:
- We had mixed responsibilities on one instance (AI, SSE, orchestration, misc.).
- Our pub/sub design fanned out every message to every pod.
- AI workloads were far heavier and burstier than anything the shared instance had seen before.
- weak per-flow observability, so we knew Redis was in trouble without knowing exactly which flows were responsible
This incident forced us to treat Redis as a first-class architectural concern rather than a shared cache, and made isolation, observability, and pub/sub design immediate priorities.
Phase 3: Defining the Redis workstream
After that incident, we kicked off a focused workstream around Redis with a simple north star:
“Stable at today’s traffic, designed for 10x headroom, with a clear path to 100x.” We grouped the work into a few themes:
- Multi-instance & tiering: which flows should get their own Redis, and how do we migrate them?
- Pub/sub & SSE: how to reduce fan-out and move chatty real-time flows off the shared instance.
- AI isolation: dedicated Redis for AI caches and streaming.
- Connections & lifecycle: reduce connection storms and clean up shutdown behavior.
- Monitoring & observability: make Redis traffic debuggable from the app’s perspective.
- Durability & scaling: for the small number of flows where Redis is more than “just a cache,” and where we’ll eventually need horizontal scale, not just bigger instances.
The rest of this post is organized along those lines
Theme 1: Multi-instance & tiering strategy
The core insight
We already had clear product domains (IAM, AI, collaboration, background processing, general caching), but Redis treated them all the same – everything talked to one instance. We needed those boundaries to exist in the data layer as well.
Deciding “who gets their own Redis”
We came up with a simple classification for each Redis-using flow:
We classified each Redis-backed flow along a few dimensions:
- New vs. existing: new use cases default to their own Redis (or a non-Redis store) unless there is a strong reason to share; existing flows are evaluated based on whether they can tolerate a reset during migration.
- Authoritative vs. derived: authoritative-ish data, like sessions and some job queues, needs stronger continuity guarantees – which in practice means pairing Redis with a write-log persistence mode like AOF (see Theme 6), not just snapshots. Derived caches can be rebuilt and are fine to lose.
- Blast radius: if a flow misbehaves, does it mostly hurt itself, or can it take down something more critical like login or search?
That led to a tiered model with dedicated instances:

Each instance has a clear owner, a narrow responsibility, and its own SLOs and dashboards.
The migration tool-belt
We standardized on:
- the five-stage IAM migration pattern
- a Terraform + config setup that rolls out instances and TLS per environment
- named Redis clients in application code, plus feature flags for safe fallback during rollout
That gave us a repeatable way to break apart the shared instance without big-bang rewrites.
Takeaway: Logical product boundaries eventually become failure boundaries whether you design for them or not. Inventory your Redis flows early, classify them by continuity needs, blast radius, and traffic shape, and invest in a repeatable migration playbook – the first split is the hardest, but every one after that should be routine.
Theme 2: Making Redis observable
Before we could safely move things around, we needed better visibility.
Instance-level metrics weren’t enough
Managed Redis gave us the basics – CPU, memory, evictions, connections, and network throughput. Those are essential, but they don’t answer questions like “which key prefixes were using memory?”, “which commands were slow from the app’s perspective?”, and “which flows were sending oversized payloads?”.
A lightweight app-side wrapper
We added a central Redis client factory in our application code that wraps all Redis clients (for both old and new instances) and automatically logs:
- Slow commands (above a duration threshold).
- Large payloads, by approximate size (no raw values).
- Errors.
Each event included the command name, key prefix, payload size, and client name (for example, ai-sse, background-jobs, or sessions). We also sampled normal traffic so we could understand baseline behavior without overwhelming the logs.
What this enabled
Within days, we had:
- Clear evidence of big-key patterns, including stale heartbeats and bulky job queues
- Pub/sub slow logs tied directly to specific features, without running ad-hoc commands on the instance itself
- A fast feedback loop when a code change made Redis unhealthy
This observability work underpins almost every other improvement in this post.
Takeaway: Instance dashboards tell you Redis is unhappy; app-side instrumentation tells you which feature made it that way. The cheapest version – a thin wrapper that logs commands above a latency or size threshold, tagged with a client name is enough to convert weeks of guesswork into hours of targeted change.
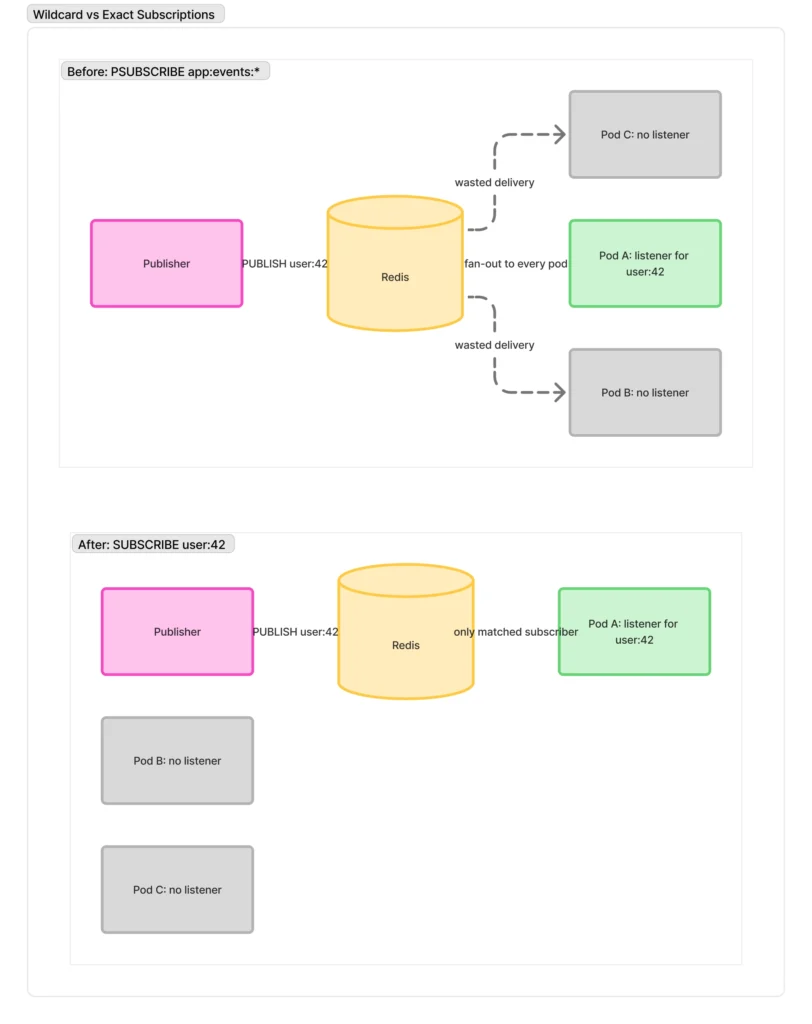
Theme 3: Pub/Sub and SSE – From wildcard fan-out to exact subscriptions
Our original pub/sub design used a broad pattern subscription: every app pod subscribed to the same prefix, every message was delivered to every pod, and each pod filtered in application code. That created predictable problems:
- Fan-out amplification: one message → many pods → many client buffers.
- Large messages (like AI SSE payloads) multiplied that effect.
- Shared bus: AI SSE, non‑AI SSE, and background job signals all used the same channels.
Step 1: Exact subscriptions
We introduced an “exact subscription” mode in our SSE infrastructure, instead of a broad PSUBSCRIBE pattern we:
- Compute the exact channel for each SSE stream.
- Subscribed and unsubscribed when the first or last listener appeared
- Kept in-memory reference counts so N listeners on the same channel don’t open N Redis subscriptions.
We rolled this out gradually while watching PUBLISH latency, slowlogs, and network egress. The impact was immediate:
- PUBLISH slowlogs for SSE traffic nearly disappeared
- network egress from Redis dropped by about an order of magnitude
Step 2: Moving SSE off the shared instance
Fixing fan-out was necessary but not sufficient. We also:
- Created a dedicated Redis instance for non‑AI SSE and collaboration
- Moved AI SSE to its own instance
- Started moving background job orchestration to its own Redis, with a longer-term path to more specialized infrastructure
Together, exact subscriptions and dedicated SSE instances removed chatty real-time traffic from the same memory and CPU pool as core caching and sessions, and moved the worst-case pub/sub stampede out of the critical path.
Takeaway: Pub/sub fan-out is how small problems become large ones. A wildcard subscription plus growing payloads can quietly multiply a feature’s footprint until it becomes an incident. If you still have pattern subscriptions in production, treat them as scheduled debt.
Theme 4: Isolating AI workloads
AI features are great at generating value, and unusual load. We were using Redis for LLM caches, session-like conversational state, and streaming updates to clients.
The problem
On the shared Redis, AI traffic had a few special properties:
- Larger keys and values
- Longer TTLs for some caches
- More bursty usage, especially during events, batch runs, and demos
That made AI a classic noisy neighbor. Under load, it put memory and throughput pressure on the same Redis used by non-AI features. We also found that some AI caches had low hit rates, because the queries were too dynamic to benefit much from long-lived cached results.
The design
We split AI’s Redis usage into three dedicated instances:
- AI cache Redis – for LLM outputs and other derived data.
- AI SSE Redis – for streaming AI responses to clients.
- AI systems Redis – for internal AI metadata and coordination that didn’t fit neatly into the first two.
Each instance is configured and monitored separately, and the application uses named Redis clients so traffic can be routed by domain and migrated safely over time. We also revisited TTL choices and shortened them where caches were large but not delivering much value.
The result
After separating AI:
- AI traffic ran on infrastructure designed for its characteristics
- The common Redis had flatter, more predictable memory usage
- Ownership became clearer, with AI teams owning their instances and dashboards
Takeaway: AI traffic forecasts age badly. Payload sizes, burstiness, and cache behavior can change quickly. Giving AI its own Redis instances and its own SLOs is much cheaper as a precaution than as a remediation.
Theme 5: Connections and lifecycle
Not all Redis issues come from keys and commands. Some come from how clients behave over time.
We found a few patterns:
- Deploys and autoscaling temporarily almost doubled connections as old and new pods overlapped
- Some flows, like upload services, created extra Redis clients per pod unnecessarily
- On shutdown, some pods closed Redis clients before draining all requests, causing noisy reconnects and unnecessary error logs
What we changed
- Consolidated Redis clients by role and pulled especially chatty components into separate services with their own lifecycle and connection pools.
- Hardened lifecycle handling with better shutdown order and health checks that distinguish critical from optional Redis dependencies.
The net effect isn’t as flashy as “10× RPS,” but it matters:
- Fewer noisy errors during deploys.
- Less load churn on Redis from reconnect storms.
- A clearer distinction between “Redis is actually down” vs “a single pod is shutting down.”
Theme 6: Durability and Redis Cluster
For most of our workloads, Redis is just a cache: if it comes back empty, we can rebuild from the system of record and pay a performance cost. But a small set of flows – sessions being the clearest example, behave more like primary state: losing them is immediately user-visible. Our managed HA tier helped with availability but had some tricky behaviors around restarts and OOM scenarios that we didn’t love.
Exploring Redis Cluster with persistence
To address that, we started a Redis Cluster + AOF persistence proof of concept. The key piece was AOF. Most managed Redis setups default to RDB snapshots, which are fine for caches but leave a gap between snapshots where recent writes can be lost, or even in some OOM scenarios lose everything entirely. For something like a session store, that means a crash can silently wipe out recent (or all) logins. AOF closes this gap by appending each mutation to a log and replaying it on restart; we run everysec for a bounded ~1s worst-case loss window. The trade-offs are real – more sustained disk I/O and larger on-disk files, but for workloads behaving like primary state, the durability is worth the cost.
Combined with Redis Cluster this gave us:
- Horizontal scale through sharding, while keeping related session keys co-located
- A bounded and well-understood loss window on restart
- Better crash semantics in the same OOM and process-kill scenarios where snapshot-only HA had previously come back empty
- No changes to session lifecycle logic beyond client configuration and key format
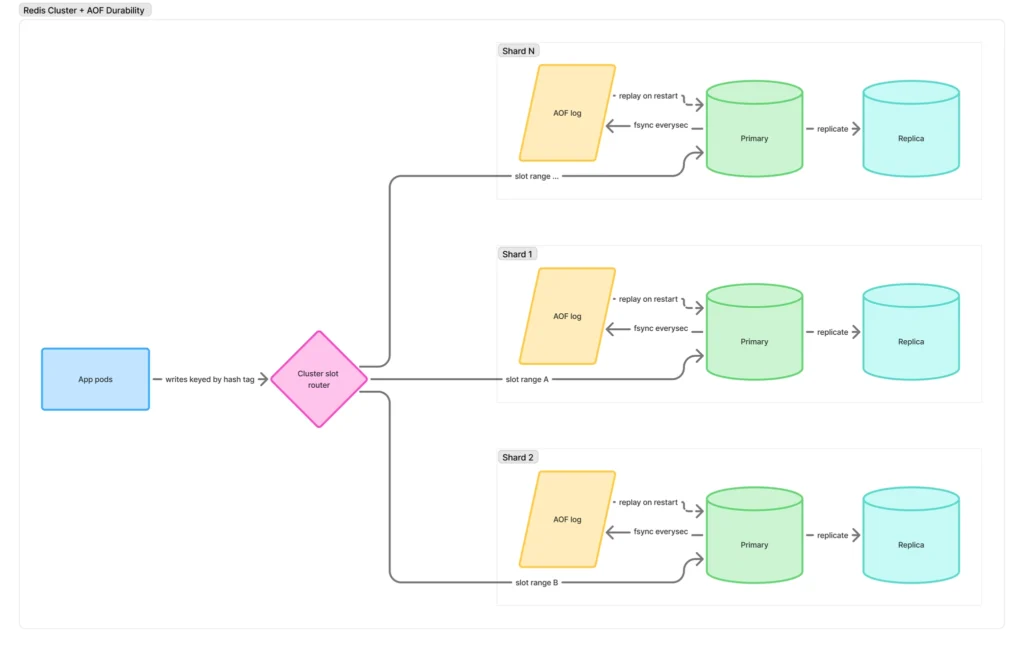
We are not moving every Redis workload to Cluster. The goal is to make Cluster + persistence a straightforward option for the small set of flows that truly need stronger durability and horizontal scale.
Takeaway: A useful question to ask of every Redis workload: “if this instance came back empty tomorrow, would that be a cache miss or an incident?” If the honest answer is “incident,” you owe that workload either a real backing store, or a Redis configuration that genuinely behaves like one – persistence, durability semantics, and a scaling story included.
Theme 7: Cleaning up “Redis misfits”
As observability improved, we found several patterns that simply didn’t belong in Redis:
- Keys that were large and long-lived, acting as semi-durable job queues.
- Legacy features that still wrote to Redis even though newer systems had replaced them.
This cleanup work helped us sharpen a guiding principle:
Redis is for hot, ephemeral data and coordination—not for long-term durable state. Where we violate that rule (sessions, a few coordination flows), we do it on purpose, with appropriate durability and scaling plans.
Takeaway: The simplest test for whether something belongs in Redis at all: would you be comfortable losing it on a restart? If the honest answer is “no,” it either needs to move out of Redis, or it needs to stop pretending Redis is a cache and get treated as primary state. The middle ground is where incidents live.
Results
So what changed at a high level?
Performance and capacity
- For the same workload, we:
- Reduced load on the primary database by keeping high-value caches and moving riskier patterns elsewhere
- Lowered and flattened Redis CPU and memory usage on the former shared instance
- With AI and SSE isolated, behavior under spikes is now more predictable
Blast radius and reliability
- An AI spike or heavy SSE workload now degrades its own Redis instance, triggers its own alerts, and does not immediately impact sessions, permissions, or general caches
- Similarly, issues in orchestration (background jobs) have a much smaller blast radius than before.
Operability
- We now have:
- Per-instance owners and SLOs.
- App-level logging that lets us see which commands and keys are slow or large.
- Runbooks for common incident patterns (e.g., slow pub/sub, rising memory).
Scale
- We’re comfortable handling 10× current traffic on the current architecture, without fundamental redesign
- We also have a clear path to 100× through:
- Redis Cluster for the small set of authoritative flows
- moving durable workloads, like job queues, off Redis
- further tiering, including colder and cheaper stores where appropriate
If we had to compress the last year of Redis work into a few principles: map flows to separate instances before traffic forces it, fix pub/sub fan-out early, invest in app-side observability, distinguish true caches from primary-state workloads, make migrations repeatable, and assume AI load will keep changing.
What’s next
We’re still actively evolving this stack.
- Move of background job orchestration onto more specialized infra.
- Rolling out Redis Cluster with persistence for the few warranted flows.
- Exploring further tiering options so we can keep Redis focused on what it does best.
We’re not done, but we’re in a much better place than the “one Redis for everything” days—and the path from here to 100× doesn’t rely on crossing our fingers and buying bigger instances.
Ironclad is not a law firm, and this post does not constitute or contain legal advice. To evaluate the accuracy, sufficiency, or reliability of the ideas and guidance reflected here, or the applicability of these materials to your business, you should consult with a licensed attorney.


